Pandas DataFrame application on dirty data
Background
Recently there’s a lot of data processing jobs coming into the lab, I will not doubt that peer logic is going to be one of the most widely used data warehouse in the future. A lot of the data processing is done on local machine with on board ram, and I decide to take some note here for people who come later.
One of the things I’ve noticed is that there’re a lot of html tags stored in review comments field, before feeding raw data coming out of Expertiza platform, we should really clean it up. There’re 2 ways of doing this, today we’re going to talk about one approach that only involves using Pandas.
To figure out the database structure, we could use some data visualization tool such as Tableau or Power BI, and apply filter on data gained. Our focus here is not how to use those tools, so we’ll jumping directly onto after data is exported into excel files.
The df.apply() function
Pandas DataFrame offers a convenient function that allows use to apply a function onto every element of itself, which is the df.apply() function. Inside the set of parenthesis use could put a one line lambda function, or the function name of a written out function.
For this tag cleaning task, we’re going to enroll a new library, the “Beautiful Soup” or bs4 library. Using built-in function of the BeautifulSoup class in bs4, use could easily extract data with all html tags ripped off.
from bs4 import BeautifulSoup soup = BeautifulSoup(string_with_tag, 'html5lib') text = soup.get_text()
if we wrap this piece of code into a function, then we could apply this function to the review comments column and clean up every row of that column. This might sound as easy as:
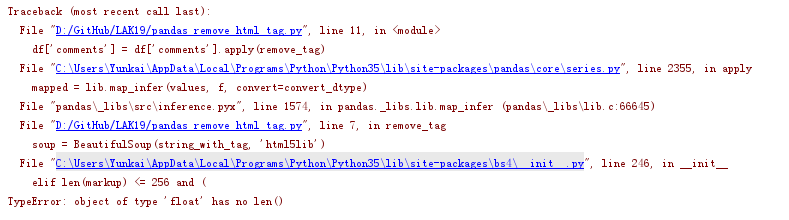
df['comments'] = df['comments'].apply(remove_tag)
But when doing that, we’d sometimes receive an error message of:
TypeError: object of type 'float' has no len()
Data type in Pandas
That’s really bizarre, since we know that when we describe the comments column, we’re getting:
Name: comments, dtype: object
*Object is the text format in pandas, just like str in python
How could a object field contain a float?
We’ll see.
By doing a try & catch (try & except in python):
try:
soup = BeautifulSoup(string_with_tag, 'html5lib')
text = soup.get_text()
except:
print(string_with_tag)
text = ''
We found that these mysterious floats are actually…
nans
That’s right, even a field with a type of object could still have empty cells! and those cells are expressed as nan. Despite of where nan resides, in object filed or any other type of fields, it is still treated as float in python.
Now that’s easy, we could approach it in two ways now: with a lazy way by keeping the try and catch structure while sacrificing some efficiency; or by using df.fillna() before applying this function to it.